https://github.com/danesparza/tplink

![]()
create CLI for any project within a few minutes with Pli!

Global installation is recommended
npm install -g @dawiidio/pli
# or
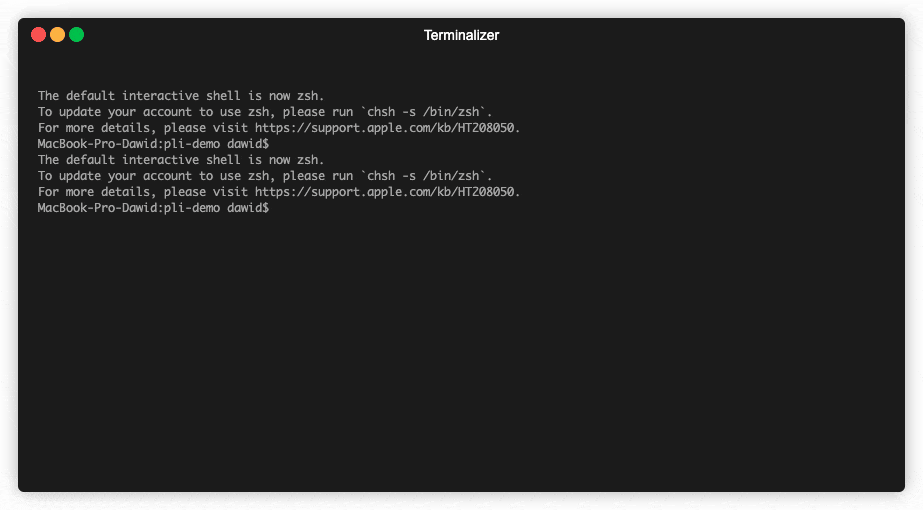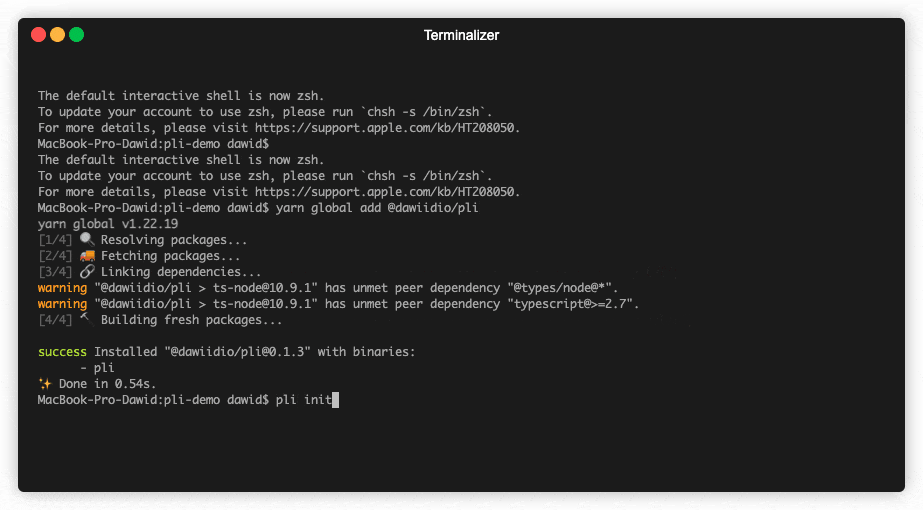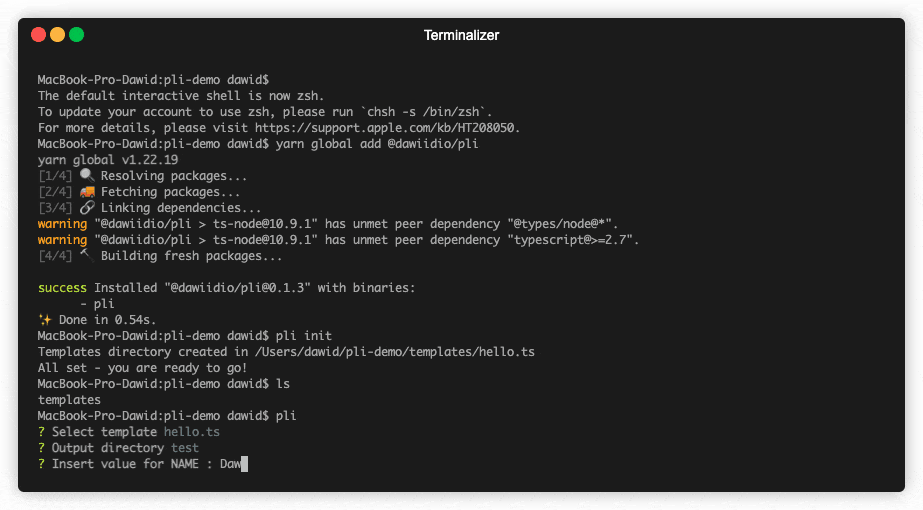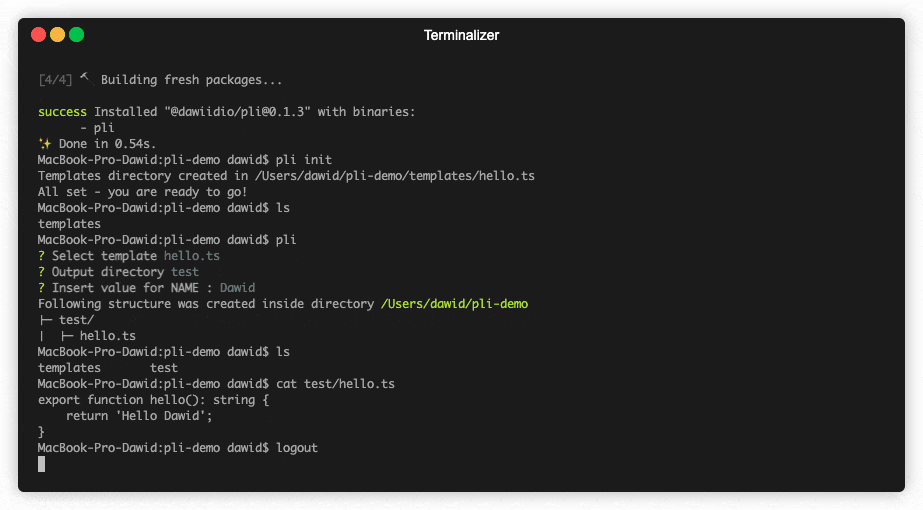
yarn global add @dawiidio/plinpm install @dawiidio/pli
# or
yarn add @dawiidio/pli You can use it also via npx
npx @dawiidio/pliinit pli in current directory
# by default pli init will produce templates directory with sample template file
pli init
# config file is optional, but if you want to create
# more complex templates it may be useful
# to generate it run
pli init -c
# by default pli init will produce typescript config file and examples, if you prefer js use
pli init -c -t jsthe above command creates templates directory and sample template file in it,
which looks like this:
export function hello() {
return 'Hello $NAME$';
}as you can see we have $NAME$ which defines pli’s variable. This variable will
be extracted and prompted to fill with value after selecting template,
you can now run pli command in current directory, pli will prompt you with below message:
? Select template (Use arrow keys)
❯ hello.js
select template hello.js by pressing enter
? Select template hello.js
? Output directory <-- type directory where file should be saved or leave it empty to save in current
? Insert value for NAME : <-- type value for name, e.g. David
when last variable is filled with value pli starts its magic and produces result file, after successful creation process you will see summary like below:
Following structure was created inside directory /your/current/working/directory
├─ hello.js
That’s it! You can see the results by opening file. For example
cat hello.jsshould return
export function hello() {
return 'Hello David';
}pli run
runs cli, default command
Commands:
pli run runs cli, default command [default]
pli init initializes pli in current directory
Options:
--help Show help [boolean]
--version Show version number [boolean]
-c, --config path to config file [string]
-d, --dry dry run, results will not be saved [boolean]
-l, --logLevel log level. Available options: error, warn, info,
debug. Multiple options separated by pipe sign "|"
[string] [default: "error"]
-o, --allowOverwriting allow overwriting output files while committing data
to storage [boolean]
-t, --templatesDirectory override templates directory
[boolean] [default: "templates"]
The above example is just the simplest one, you can create more sophisticated templates with many directories, variables and files. See examples for more
to create more powerful tools and templates the config file may be needed, run
# for typescript config file run
pli init -c
# for javascript config file run
pli init -c -t jsthe above command creates pli.config.js or pli.config.ts file in current directory,
now this is the time to create more complex templates, we will create a React
component template with support for css modules.
run
mkdir templates/\\$NAME$
touch templates/\\$NAME$/\\$NAME$.tsx
touch templates/\\$NAME$/\\$NAME$.module.cssin templates/$NAME$/$NAME$.tsx file add
import React, { FunctionComponent } from "react";
import styles from './$NAME$.module.css';
interface $NAME$Props {
}
export const $NAME$:FunctionComponent<$NAME$Props> = ({ }) => {
return (
<div className={styles.$NAME$Root}>
Component $NAME$
</div>
)
};now we have a template for React component, but we want to have support for css modules, so we need to add css file for it.
in templates/$NAME$/$NAME$.module.css file add
.$NAME$Root {
}now we have a template files for React component with css module support, and it will work just fine now, but we can make it even better.
in pli.config.ts file add
import { Template, IConfig, TemplateVariable, ITemplateVariable, IVariableScope } from '@dawiidio/pli';
const config: IConfig = {
templates: [
new Template({
// readable name, instead of "$NAME$" you will see "React Component" in cli
name: 'React Component',
// if you want to extend from existing template in templates directory you need to provide its name
id: '$NAME$',
// all will be generated relative to src/components directory
defaultOutputDirectoryPath: 'src/components',
variables: [
new TemplateVariable({
// variable name, it will be replaced with value in template files
name: 'NAME',
// you can pass default value for our variable
defaultValue: 'MyComponent',
// let's add some validation for our variable
validate: (value: string) => {
if (value.length < 3) {
throw new Error('Name must be at least 3 characters long');
}
}
}),
new TemplateVariable({
// variable name, it will be replaced with value in template files
name: 'DIRNAME',
// this variable will subscribe from NAME variable, so it will be updated when NAME is updated
defaultValue: '$NAME$',
ui: {
// you can also hide variables from user, so it will be used only for internal purposes
hidden: true
}
}).pipe(
// you can pipe variable value and trnasform it as you want,
// in this case we will replace all spaces with dashes
// and then we will convert all letters to lowercase
// so if we type "My Component" as NAME variable value
// DIRNAME will be "my-component"
(value: string, variable: ITemplateVariable, scope: IVariableScope) => value.replace(/\s/g, '-').toLowerCase()
)
],
})
]
}
export default config;after adding config file we can run pli, if you set $NAME$ to e.g. TestFilters you will see below message:
Following structure was created inside directory /myProject/src/components
├─ TestFilters/
│ ├─ TestFilters.module.css
│ ├─ TestFilters.tsx
You can create variables in your templates by using notation with dollars $MY_VAR$.
Variable name is case-sensitive, so $my_var$ and $MY_VAR$ are different variables.
Variable name can contain only letters, numbers and underscores.
Variables can be used in any file, or directory name,
or in other variable defaultValue field which means that variable will
subscribe to changes of variables passed in defaultValue.
You can use variables also in outputMapping in template config.
Variables are organised in scopes, so you can have variables with the same name in different scopes. It is useful when you want to access variables from different template. For example if you want to add template as an entry to another template you can use variables from parent template i child. Also, variables from child will be extracted and prompted to fill with value when selecting parent template.
Example:
import { Template, IConfig, TemplateVariable } from '@dawiidio/pli';
const childTemplate = new Template({
name: 'Child',
id: 'child.ts',
variables: [
new TemplateVariable({
name: 'CHILD_VAR',
defaultValue: 'child'
})
]
});
// parent template will prompt for PARENT_VAR and CHILD_VAR
const parentTemplate = new Template({
name: 'Parent',
id: 'parent.ts',
variables: [
new TemplateVariable({
name: 'PARENT_VAR',
defaultValue: 'parent'
}),
],
entries: [
childTemplate
]
});
const config: IConfig = {
templates: [
parentTemplate,
]
}
export default config;You can map output of template which allows you to create more complex templates, for example you can create template which will remap child template output to different directory or filename.
import { Template, IConfig, TemplateVariable } from '@dawiidio/pli';
const childTemplate = new Template({
name: 'Child',
id: 'child.ts',
variables: [
new TemplateVariable({
name: 'CHILD_VAR',
defaultValue: 'child'
})
]
});
const parentTemplate = new Template({
name: 'Parent',
id: 'parent.ts',
variables: [
new TemplateVariable({
name: 'PARENT_VAR',
defaultValue: 'parent'
}),
],
entries: [
childTemplate
],
outputMapping: {
// note thath you can not use CHILD_VAR in this scope
'child.ts': '$PARENT_VAR$.ts',
'parent.ts': '$PARENT_VAR$_somePostfix.ts',
}
});
const config: IConfig = {
templates: [
parentTemplate,
]
}
export default config;